Deep Reinforcement Learning: Benchmarking, Algorithms and Applications
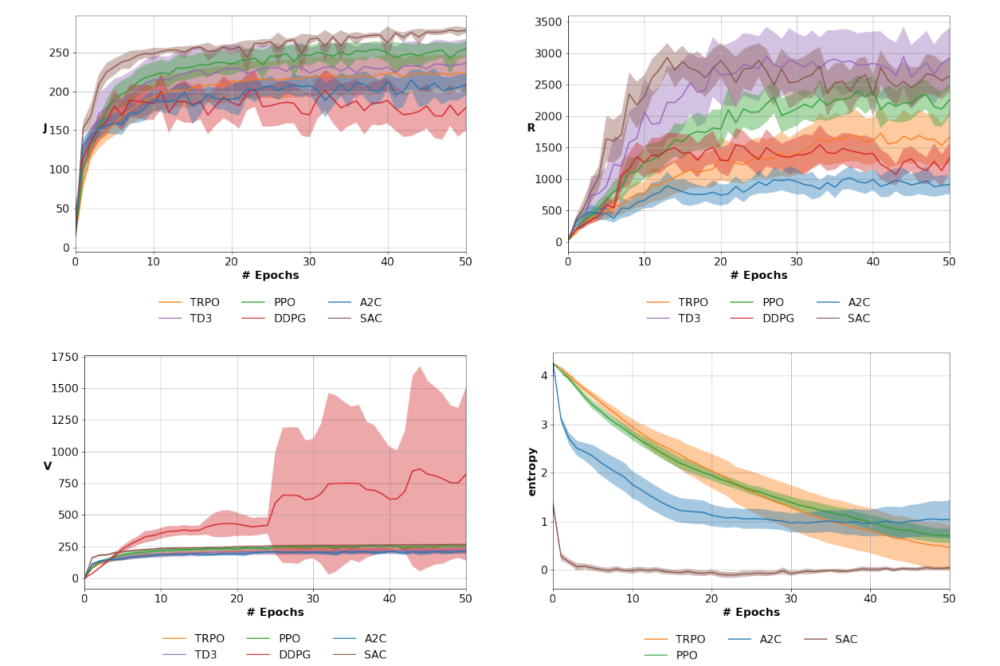 Tateo_Davide_Deep Reinforcement Learning_Benchmarking algorithms and applications_Figure1
Tateo_Davide_Deep Reinforcement Learning_Benchmarking algorithms and applications_Figure1Figure 1: Discounted return (J), Cumulative return (R), Value function on the initial state (V), and policy entropy on the MuJoCo Hopper-v3 Task
Davide Tateo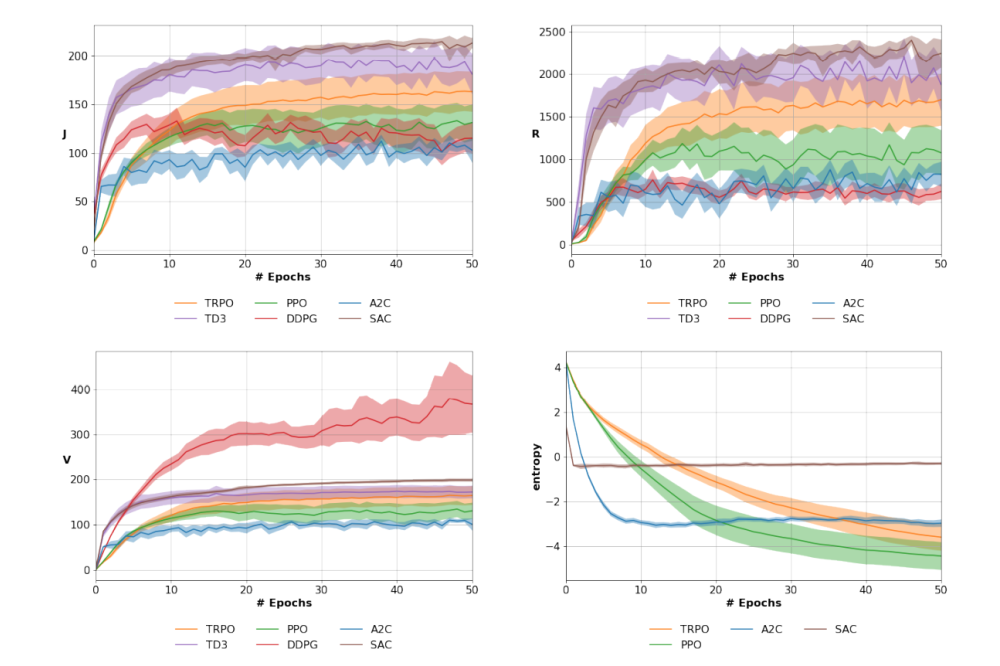 Tateo_Davide_Deep Reinforcement Learning_Benchmarking algorithms and applications_Figure2
Tateo_Davide_Deep Reinforcement Learning_Benchmarking algorithms and applications_Figure2Figure 2: Discounted return (J), Cumulative return (R), Value function on the initial state (V), and policy entropy on the PyBullet HopeprBulletEnv-v0 Task
Davide TateoIntroduction
Deep Learning is the major component of the success of most new Artificial Intelligence applications. A new promising field is the application of these techniques to Reinforcement Learning (RL), where they can be used to build AI that can beat humans in complex games, such as chess and Go, in the development of autonomous driving applications, or bring robotics application to the next level. However the field is relatively new, and the scientific method has not been adopted properly to assess the quality of the results in this field. Our objective is to found the Deep RL research starting from the basics, by first measuring with extensive benchmarks of the performances of the existing algorithms, and using the insights of this analysis, find out the best components of each approach to build novel and better deep reinforcement learning algorithms.
Methods
We considered many standard Reinforcement Learning methods such as DDPG [1], A2C [2], TRPO [3], PPO [4], TD3 [5] and SAC [6]. To ensure the statistical relevance of our results, web evaluated the algorithms over 25 runs and we reported mean and confidence intervals. Differently from standard RL research, not only we evaluate the performance w.r.t. cumulative return, but also we consider the —more appropriate in terms of theorydiscounted cumulative return, the policy entropy, and the value function in the initial state. Indeed, the discounted cumulative return is more appropriate than the cumulative one as is the actual measure the RL algorithms are maximizing. This metric is also more relevant in an infinite horizon scenario, where the undiscounted one diverges. The (expected) value function of the initial states is also a very important metric, as it is equivalent to the objective function, i.e. the cumulative discounted return. As deep actor-critic approaches are estimating the value function from data, by looking at the value function of the initial states we can understand if there is a problem of overestimation or underestimation. This metric, often neglected in current literature, gives us crucial insights to understand the properties of deep RL algorithms.
Results
We developed a Reinforcement Learning library called MushroomRL. This library provides a clean implementation of Deep Reinforcement Learning algorithms. To validate the implementation of the algorithms, we build an extensive benchmarking suite, MushroomRL Benchmark. We validated our implementation on the most common RL Benchmarks.
Discussion
The analysis of the results shows, as expected, that the cumulative reward and the cumulative discounted reward are not equivalent metrics: different algorithms may be regarded as better depending on the chosen metric in different tasks. A slight modification of the same environment (e.g. MuJoCo vs PyBullet environment) impacts massively the performance of the approaches. It is evident the importance of the value function of the initial state to understand the behavior of an algorithm, as overestimation issues can impact the overall performance as seen in DDPG. In general, the results show that is fundamental to improve the design of Deep RL experiments, in terms of the number of seeds, the variety of environments, and the performance metrics.