Caption
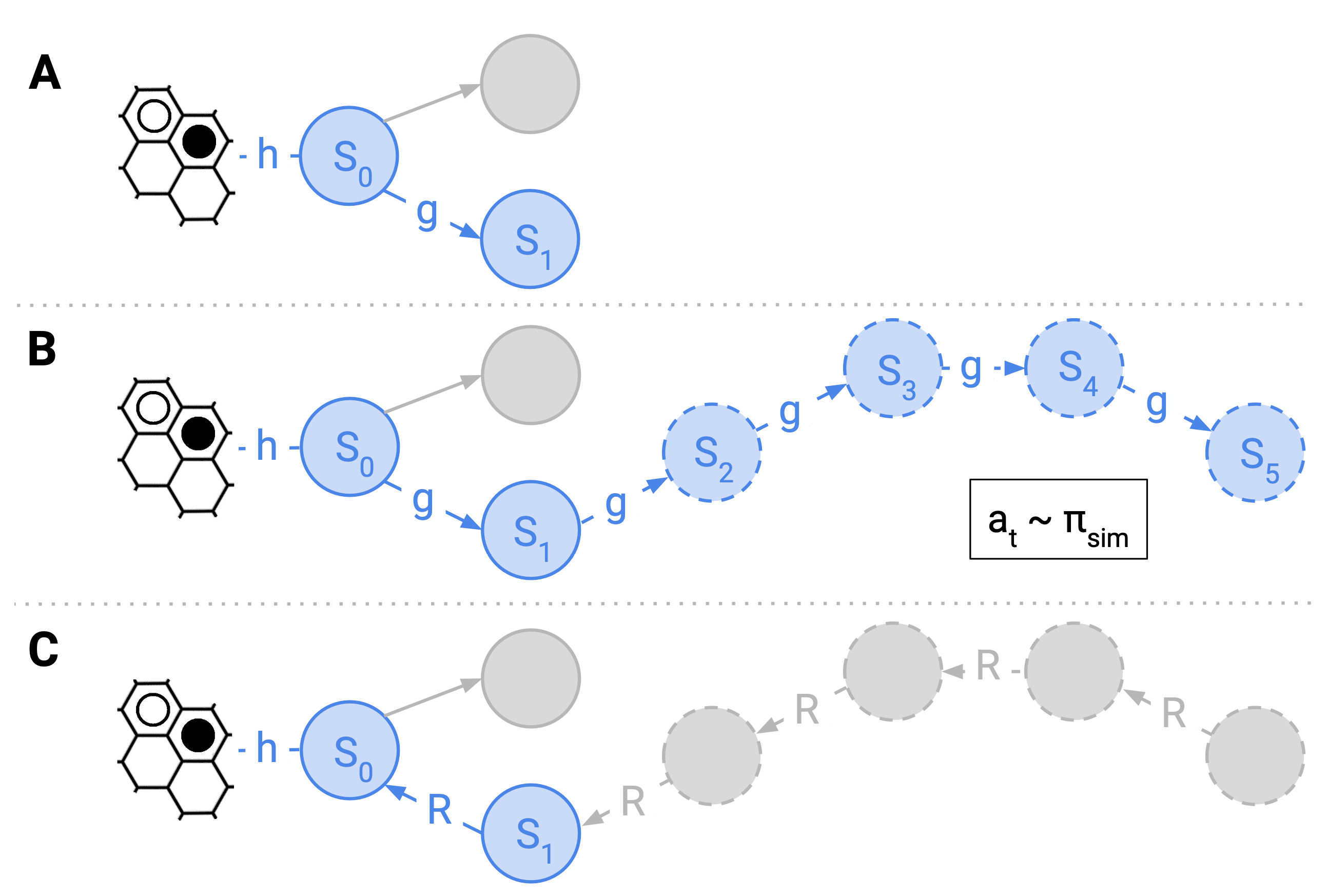
Figure 1: This figure presents the 3 steps of our VE-PGS algorithm. A) The method starts from the current state s0. B) By running the simulation policy the search tree is temporarily expanded and collects intermediate rewards. C) The rewards obtained during the simulation phase are propagated back to the node s0. These steps are repeated until convergence or a predefined computation budget.