Caption
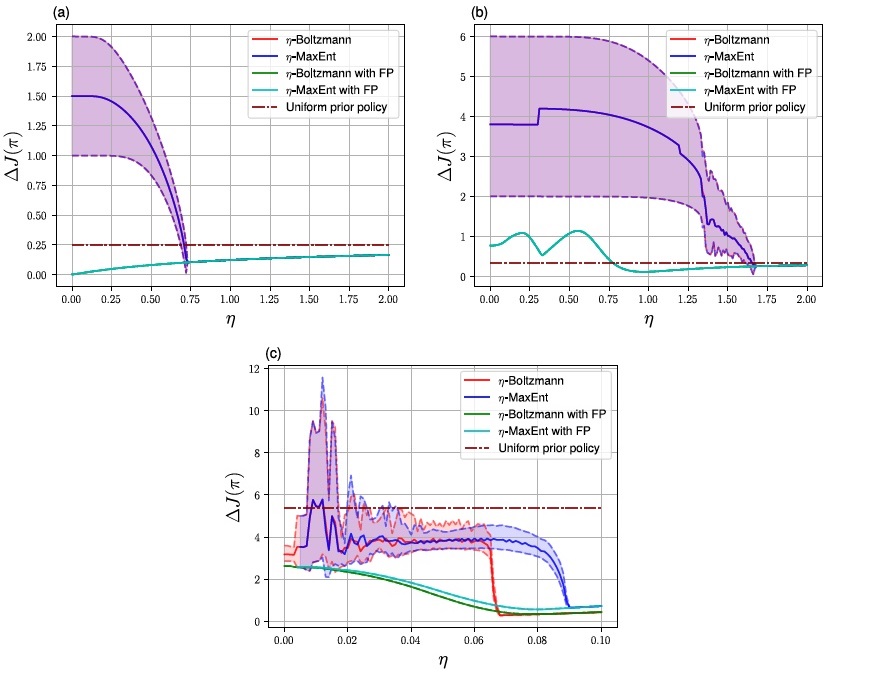
Figure 1: Mean exploitability over the final 10 iterations. Dashed lines represent maximum and minimum over the final 10 iterations. (a) LR, 10000 iterations; (b) RPS, 10000 iterations; (c) SIS, 10000 iterations. Maximumentropy (MaxEnt) results begin at higher temperatures due to limited floating point accuracy. Temperature zero depicts the exact fixed point iteration for both η-MaxEnt and η-Boltzmann MFE. In LR and RPS,η-MaxEnt and η-Boltzmann MFE coincide both with and without fictitious play (FP), here averaging both policy and meanfield over all past iterations. The exploitability of the prior policy is indicated by the dashed horizontal line.