
Projects
Hessian scientists of various disciplines are using High Performance Computers for their research.
Hessian scientists of various disciplines are using High Performance Computers for their research.
Displaying 1 - 5 of 5
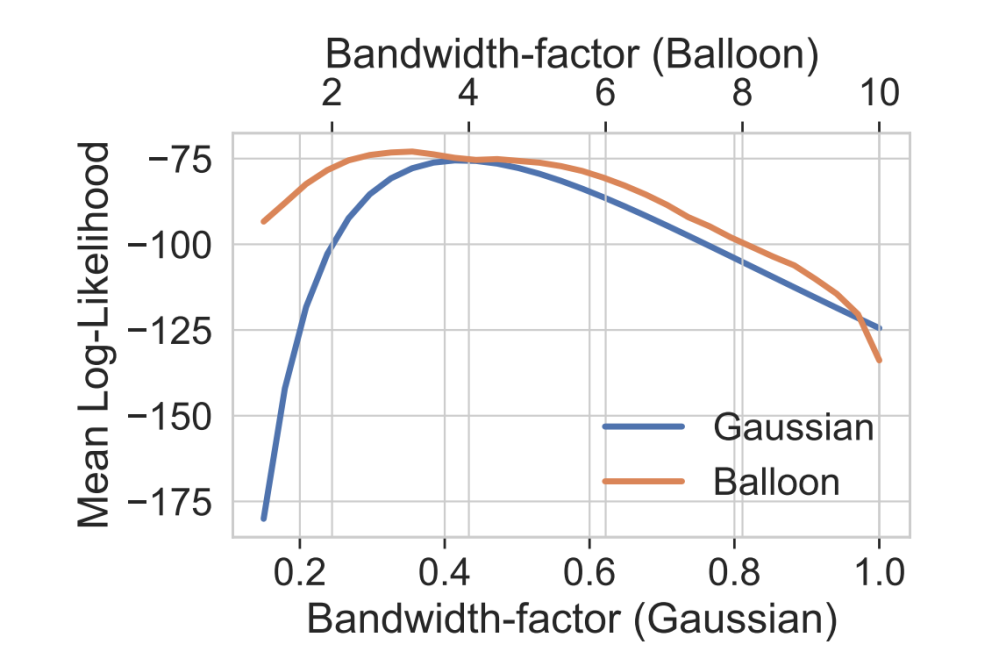
The Nonparametric Off-Policy Policy Gradient (NOPG) is a policy gradient algorithm to solve reinforcement learning tasks ...

The aim of the project is to develop a new family of optimization algorithms to handle convex constraints and evaluate ...
Precise models of the system dynamics are crucial for model-based control and reinforcement learning (RL) in autonomous ...
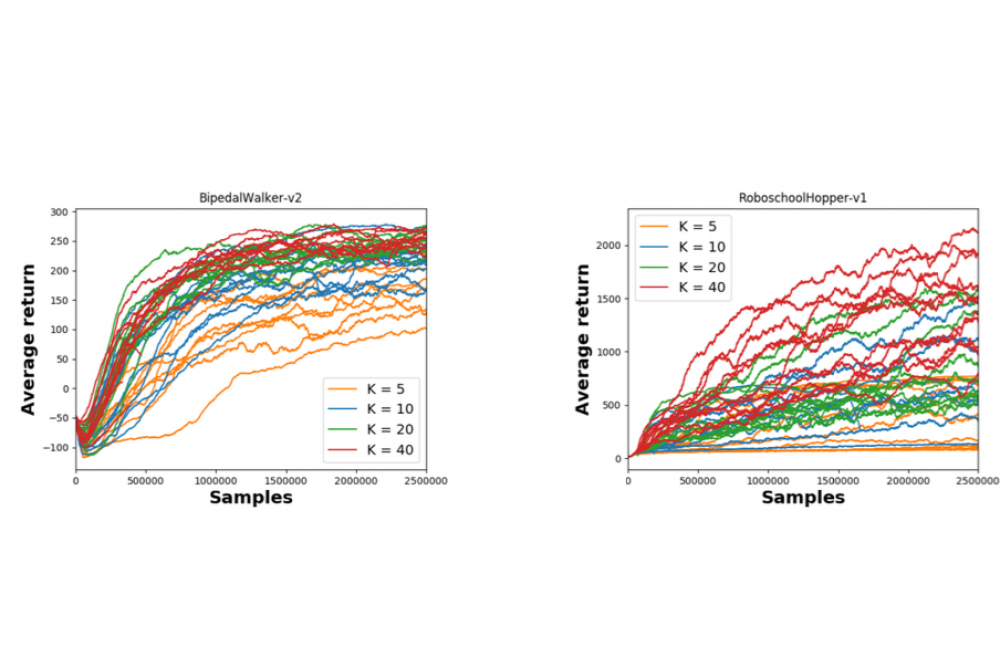
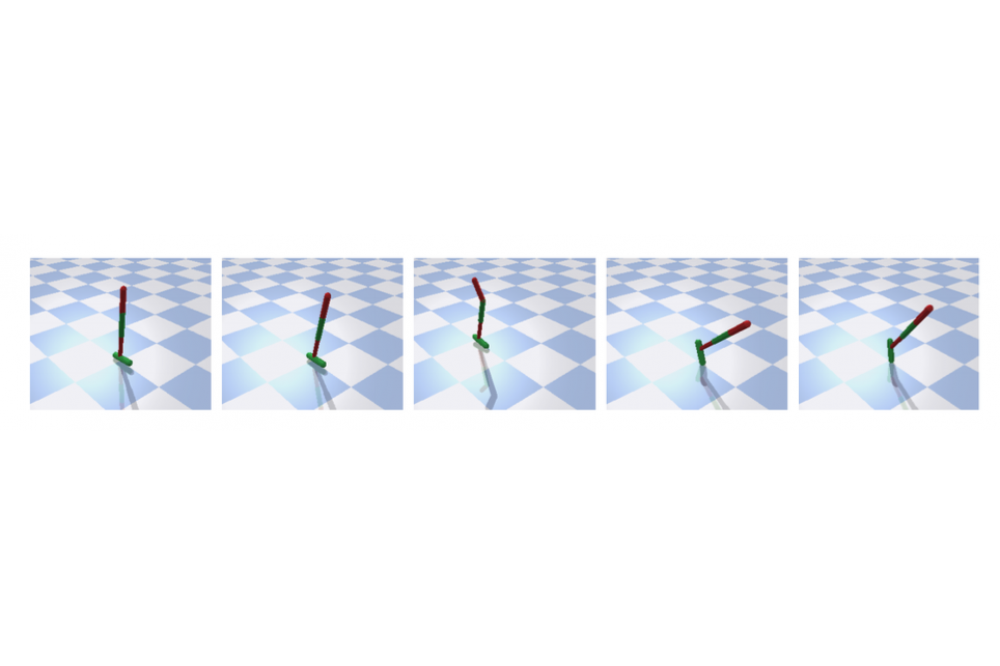
Deep Reinforcement Learning can solve difficult high dimensional tasks, by exploiting the expressive representation ...
Identifying scalability bugs in parallel applications is a vital but also laborious and expensive task. Empirical ...